Real policy rollouts after training on HABIT, a large-scale dataset of robot manipulation demonstrations collected with a human sharing the workspace. The clips below are drawn from its 60 tasks, spanning all three human-robot interaction roles.
Existing robot manipulation datasets are collected in human-absent settings, so policies trained on them can perform a task in isolation but fail to act appropriately when a person is present. HABIT closes this gap, with the goal of robot policies that can work alongside people.
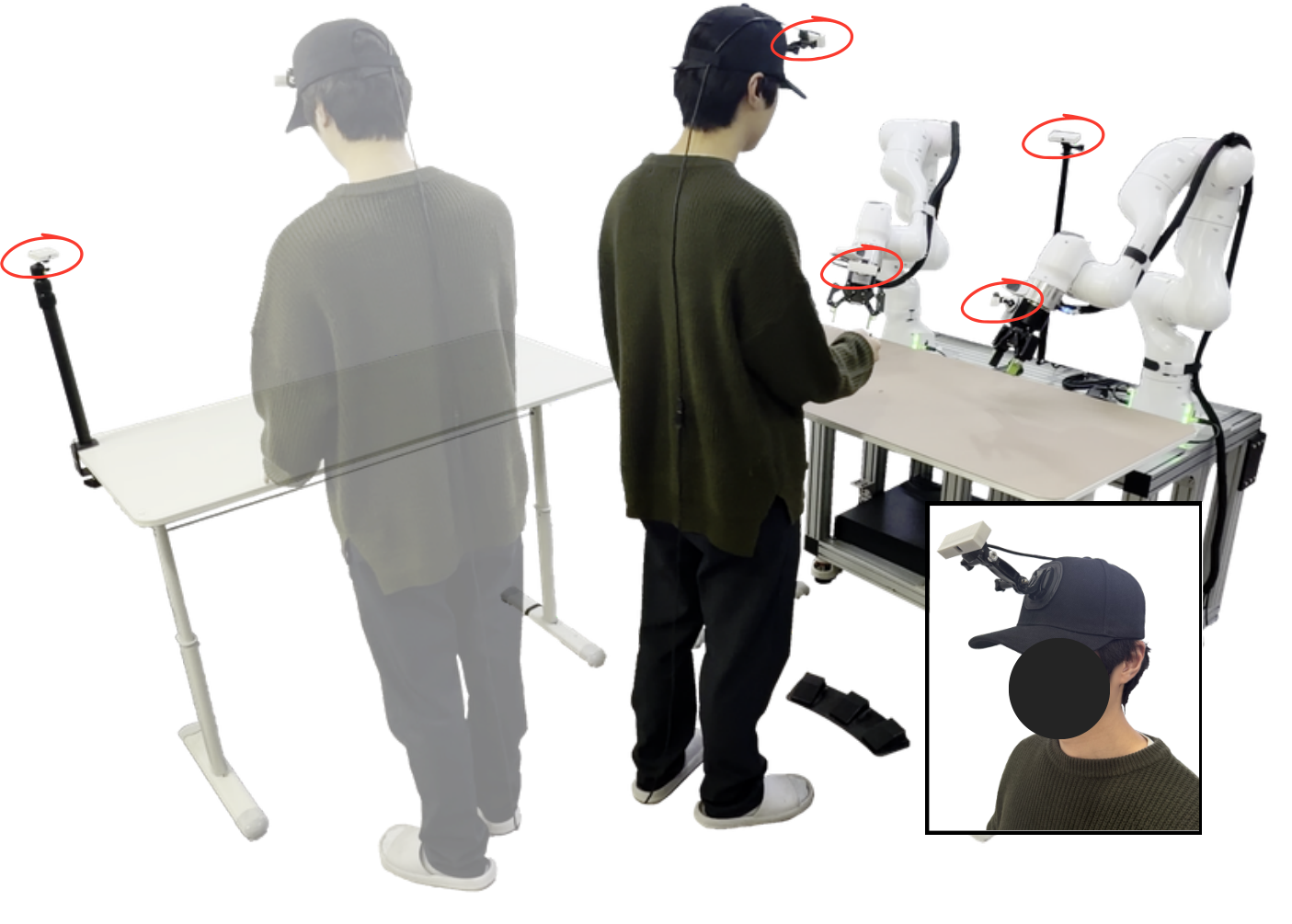
The collection setup
Bimanual manipulation captured with two Franka Research 3 arms and five synchronized RGB cameras, with a human sharing the workspace in every episode.
Robot side (3): two wrist cameras and one egocentric view facing the shared workspace.
Human side (2): a head-mounted egocentric view and an exocentric view of the whole interaction.
0
Episodes
0
Hours of manipulation
0
Tasks
0
Unique human-robot subtask pairs
Task design
Three interaction roles
Human-robot interaction takes many forms. To capture this diversity, we adopt three roles from the Human-Robot Interaction (HRI) literature, each defined by how the human and robot relate within a subtask.
Collaborator
20 tasks · 3,198 episodes
Act together
The human and robot jointly accomplish a shared goal through direct physical interaction (e.g., handing over an object or jointly holding a bucket), and the robot must coordinate with the human both spatially and temporally.
Coworker
20 tasks · 3,969 episodes
Work side by side
The human and robot perform separate tasks while sharing only the workspace; the robot must avoid collisions with the human to ensure safety.
Supervisor
20 tasks · 3,396 episodes
Follow instructions
The human directs the robot through explicit cues such as gestures or demonstrated actions, and the robot must infer the human's intent from visual input alone.
A preview of HABIT, spanning the three human-robot interaction roles at its core: Collaborator, Coworker, and Supervisor.
A single instruction such as "clean the shelf together" is too ambiguous to elicit consistent demonstrations. So each task follows a task workflow: a directed graph of human (Hi) and robot (Ri) subtasks that fixes how the two agents divide and sequence the work.
The task workflow, in motion
A representative workflow per role, with the robot's and human's cameras in sync.
Plays through automatically — the highlighted subtask advances with the video. Click any node to jump to that step.
Robot viewHuman view
Table Service · Collaborator. The human and robot take turns; each subtask waits for the partner to finish the previous one.
Robot viewHuman view
Shelf Cleaning · Coworker. Two independent chains that share only the workspace.
Robot viewHuman view
Cup on Coaster · Supervisor. The robot reads the human's placement cue from vision alone.
How we collected the data
Reactive interaction
The rule behind every HABIT recording: each robot action responds to a cue the cameras can actually see.
Because the robot operator knows the subtask sequence in advance, they could pre-execute the next subtask from memory rather than reacting to the human. For example, the robot operator might begin reaching toward a target object before the human ever points to it.
This quietly breaks learning: the cue that triggers the action then falls outside the camera input, so no policy could ever recover the behavior from the recorded data.
"Each operator acts only after directly observing the partner's behavior. We prohibit any coordination signal that is not captured in the recorded observations, so every demonstrated action is grounded in cues that are also available to the policy."
Reactive interaction. The robot operator acts only after an observable cue, so every trigger is captured in the data.
Beyond reactivity
Eliciting human-aware behavior
Reactivity alone does not guarantee the human-aware behavior we want, so the collection protocol adds three deliberate design choices.
Yielding under safety-first priority
The robot yields to keep the human safe
Human safety is the overriding constraint. Whenever the robot is about to collide with the human or a human-held object, the robot operator decisively retracts the arms rather than continuing the trajectory, so yielding becomes the robot's default recorded response.
Temporal adaptation
Matching the human's tempo
The human operator's movement speed is deliberately varied across episodes, so the data captures the robot adapting its pace to the human rather than moving at a single fixed cadence.
Gesture grounding
No shortcut to the gesture
The risk is not that the robot follows words, but that it takes a shortcut and acts before the human has even pointed. So during collection, the human operator waits a random interval before gesturing, forcing the recorded behavior to depend on actually reading and grounding the gesture.
Experiments
Human-aware behavior emerges from data
We fine-tune two open-source VLAs, π0.5 and GR00T N1.6, on a six-task subset. Training steps and batch size are held fixed, so the dataset is the only variable. Each number is the mean over 20 trials.
What is Robot-only? The conventional baseline: the same tasks, environment, and robot operator as HABIT, but recorded with no co-present human. The robot does only its own share of the work in an empty workspace, and for Supervisor tasks it receives the same indexed instruction without the human's pointing gesture.
Success rate across the six evaluation tasks
Higher is better. Collaborator tasks need a human partner, so Robot-only is not applicable.
Robot-onlyHABIT (ours)
HABIT improves success on every comparable task, with the largest gains on Coworker tasks, where workspace overlap demands reactive yielding (Box Packaging: 10% to 85% for π0.5). The same pattern holds for GR00T N1.6, so the gain comes from the data: human-present demonstrations teach what conventional Robot-only data cannot.
Robot-only vs. HABIT, side by side
Real policy rollouts on the four tasks that have a Robot-only baseline. Watch how the HABIT policy yields and follows the human where Robot-only does not.
Each role has a characteristic failure mode. HABIT instills the behaviors that human-absent data cannot teach.
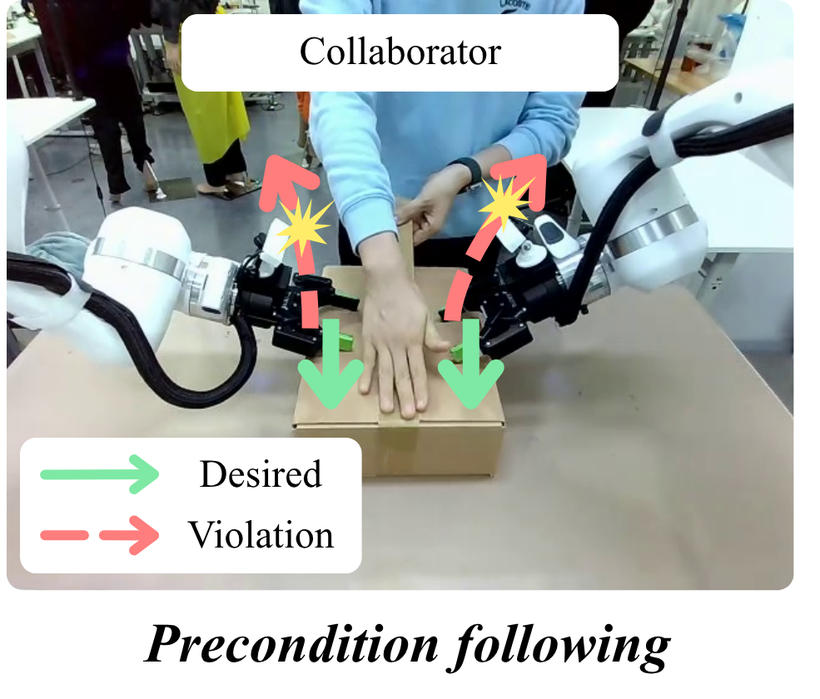
What each failure looks like. The robot should follow the desired path (green), but a violation (red) means acting before a precondition is met (Collaborator), colliding in shared space (Coworker), or ignoring the human's gesture (Supervisor). The charts below measure how often each occurs.
Two evaluation tasks per role, both models shown. Lower is better; Robot-only is not applicable for Collaborator tasks (which need a human partner).
Robot-onlyHABIT (ours)
HABIT sharply reduces every role-specific failure across both models. The improvement is largest for π0.5 on Waste Sorting, where collisions fall from 60% to 0%.
A strong prior for new tasks
Mid-training π0.5 on HABIT, then fine-tuning on a new task, beats fine-tuning from scratch (labeled direct fine-tuning in the plot below) at every data budget. HABIT transfers as a reusable prior for human-robot interaction.
Direct fine-tuningHABIT mid-training + fine-tuning
On Waste Sorting, mid-training with just 50 demonstrations matches direct fine-tuning at 200. On Shelf Cleaning, direct fine-tuning never exceeds 45% even at 200 demos, while mid-training reaches 60% with only 100 demonstrations.
Cite
BibTeX
@article{song2026habit,
author = {Jaehwi Song and Suchae Jeong and Byeongguk Jeon and Sungdong Kim and Minjoon Seo and Hyungmok Son and Kimin Lee},
title = {HABIT: Human-Aware Behavior and Interaction Training Dataset for Robot Manipulation},
journal = {arXiv preprint arXiv:2606.31682},
year = {2026}
}